Getting data to the Cloud
DataOps
Get access to all your technical data in real time, and find data easy in a unified namespace layout
What is DataOps?
DataOps, short for Data Operations, is an agile methodology designed for the improved management, automation, and integration of data flows across an organization. It emphasizes collaboration between data scientists, engineers, and IT professionals to streamline the data lifecycle, from collection to processing and analysis. DataOps aims to increase the speed, accuracy, and efficiency of data analytics, ensuring data quality and facilitating a culture of continuous improvement in data management practices.
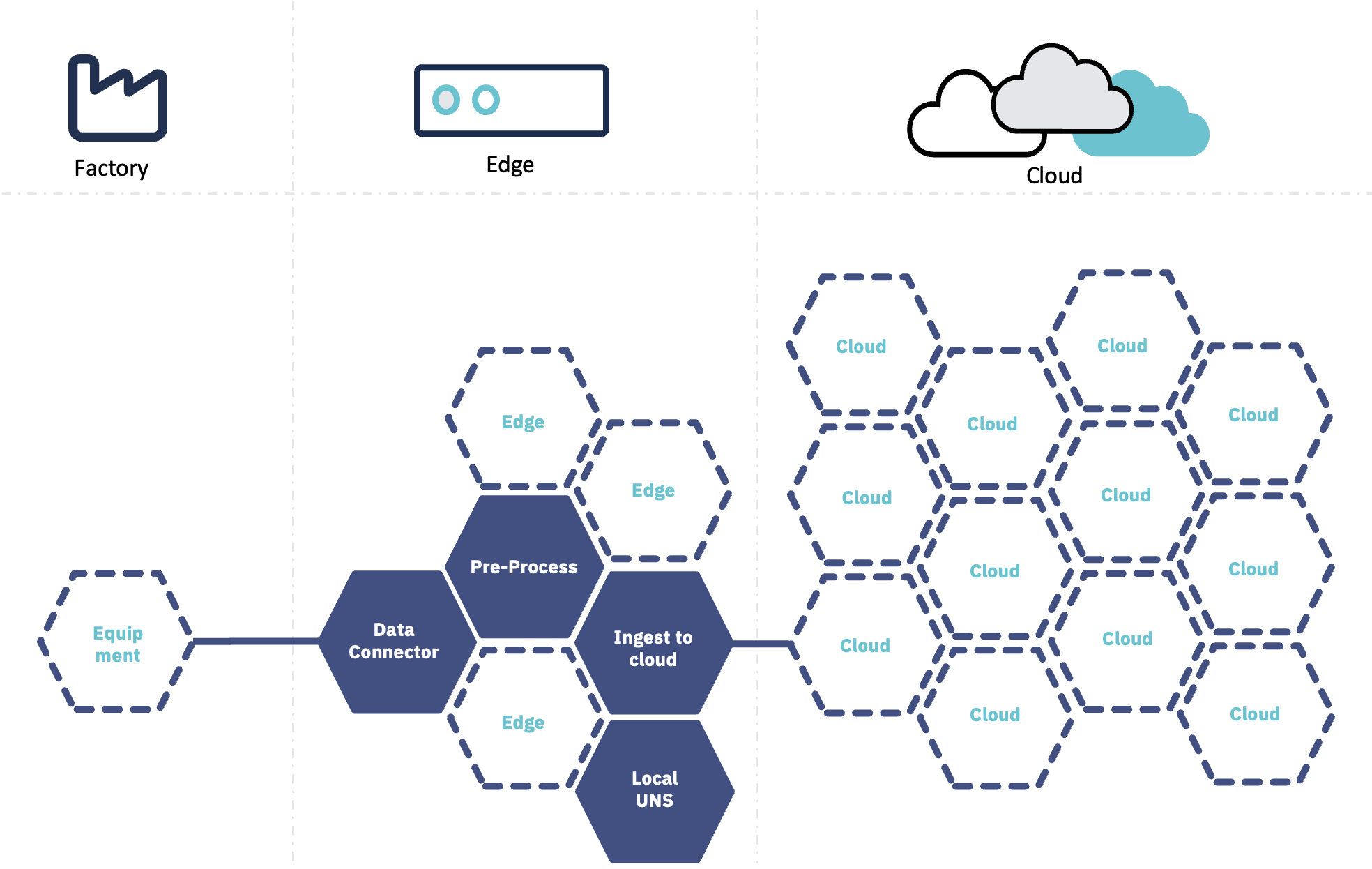
In this section we will primarily discuss the dataflow from physical equipment to storing data in the cloud, for further analysis. Tricloud Nexus establishes the foundation for a fully integrated DataOps solution enabling vastly accelerated digital continuous improvement process. See use case examples eg. Vision AI and vibration AI as examples of how this can be accomplished.
Tricloud Nexus - Data collection process
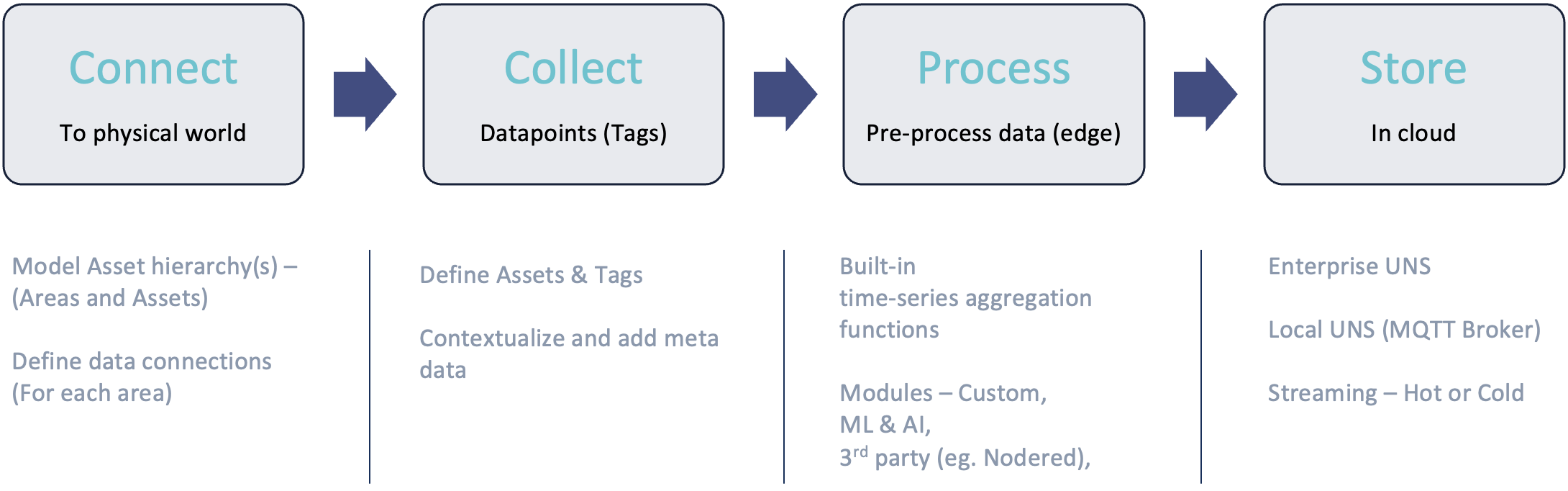
Connect
Accessing data by establishing connectivity to equipment and sensors is key in an industrial IoT solution.
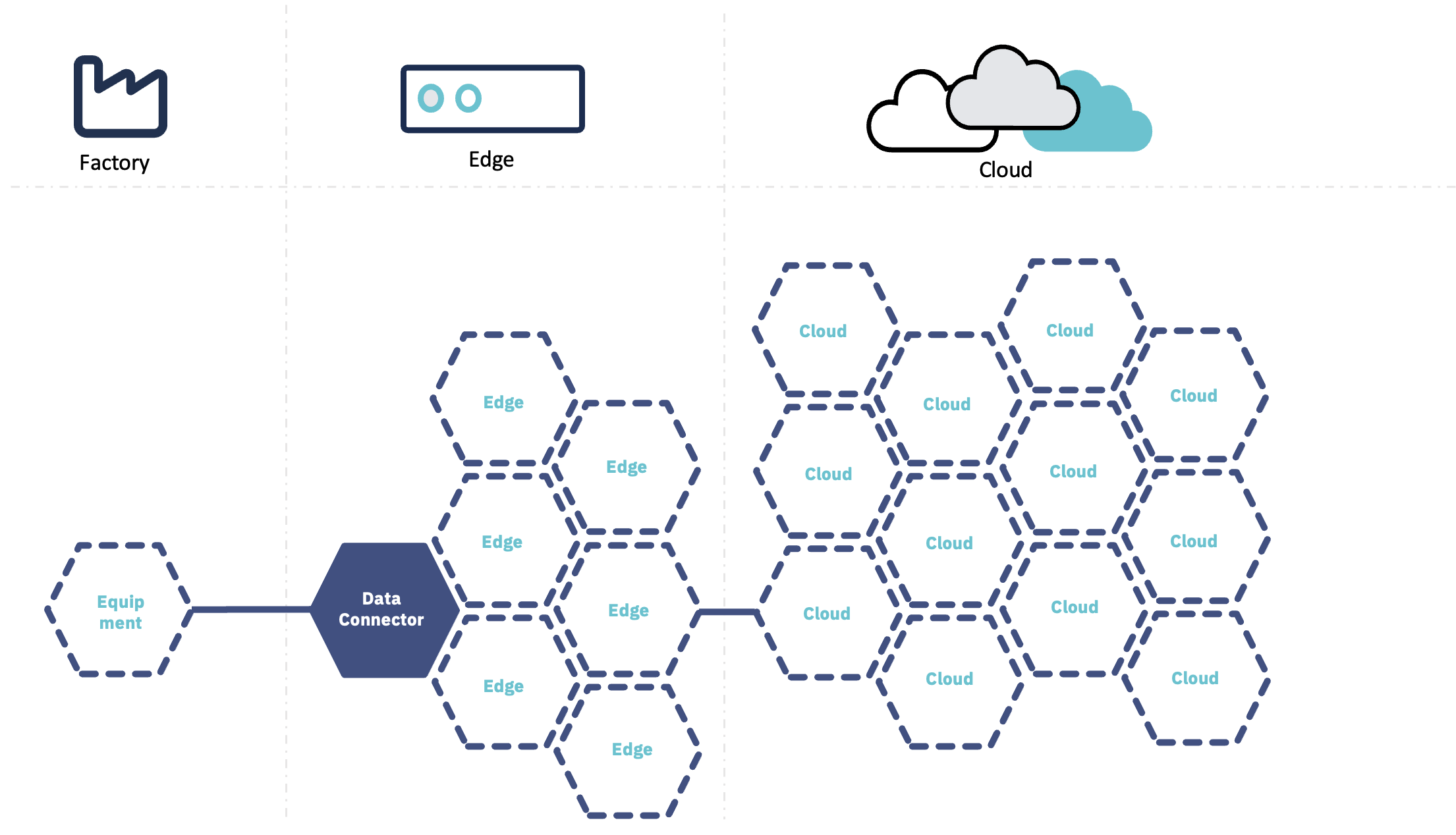
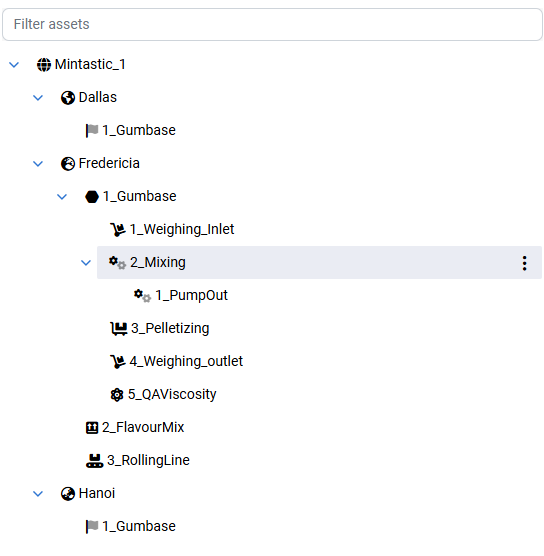
In Tricloud Nexus you start out by defining an Asset Hierarchy that models your real-world assets. Here you specify your Data Sources, that allows you to connect to many different industrial protocols.
Tricloud Nexus streamlines the process of connecting to data sources through dedicated modules downloadable to the edge from the module store. This repository contains numerous built-in modules that facilitate communication with systems utilizing protocols such as OPC-UA, MQTT, Modbus, File shares (SMB), SFTP, and others.
Integration with other systems can be facilitated either by importing third-party communication protocols into the module store or by developing custom-built modules using the Nexus SDK for data sources. The Nexus SDK supports C# and Python, enabling fast and straightforward implementation of additional communication protocols, if necessary.
Collect
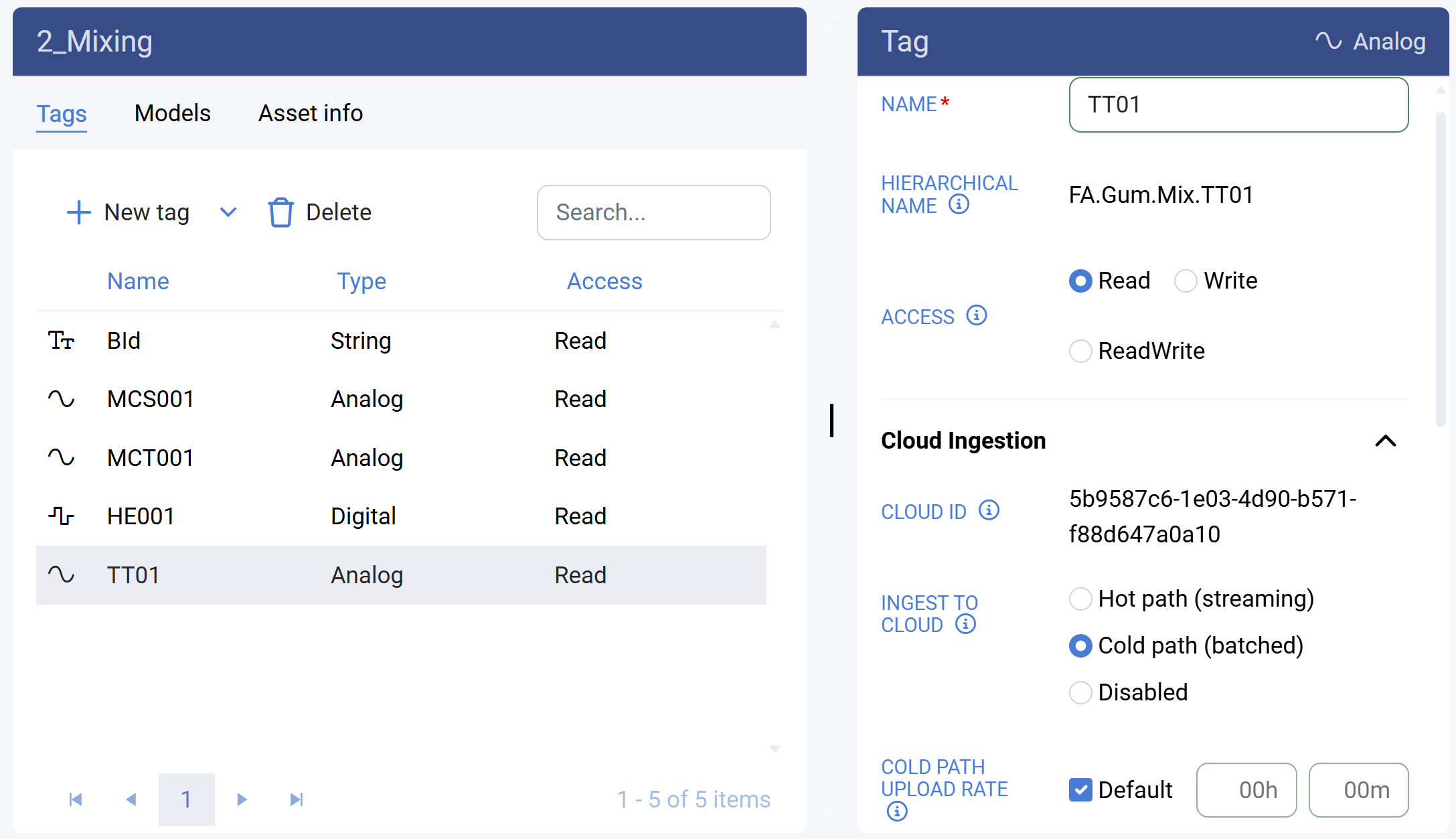
Once the Asset Hierarchy and Data Sources have been established, the next step is to define the data being collected. The Asset hierarchy supports the ISA 95 part 2 naming standard, providing a standardized structure for organizing assets. Data points (tags) associated with each asset can be managed in various ways, depending on the specific requirements.
- The management portal contains an Asset hierarchy designer tool, for easy and fast implementation of small to medium sized solutions.
- If an Asset Hierarchy structure and meta data exist in another system, Tricloud Nexus can import the configuration.
- The platform also offers the comprehensive Nexus REST Api, ideal for cases where data resides in an engineering tool, allowing for dynamic integration and faster configuration processes.
- Contextual information can be added and stored alongside the collected data as metadata, enhancing its utility for data scientists and other users.
Tricloud Nexus supports multiple Asset Hierarchies, enabling separation of different logical spaces in your installation. For instance, you can establish separate hierarchies for manufacturing processes and building automation systems, or even design hierarchies for individual production facilities.
The Tricloud Nexus platform includes full traceability and version handling, making rollback to previous versions easy, and thereby ensuring a robust environment for system development and operation.
Asset hierarchy in Tricloud Nexus
Process
Having defined your data points (tags) within an Asset Hierarchy, preprocessing the data before sending it to the cloud becomes possible. This preprocessing step offers significant advantages, not only in terms of minimizing the volume of data collected, but also in minimizing the associated costs of operating the cloud platform.
Tricloud Nexus incorporates built-in data aggregation functions for easy and convenient preprocessing of data prior to storage in the cloud. These functions include computing minimum and maximum values, time- and value-weighted averages, and more. Additionally, preprocessing of data at the edge can be facilitated by modules installed from the module store. These modules can range from ML/AI-based solutions to third-party tools like NodeRed and others, enabling versatile preprocessing capabilities before transmitting the data to the cloud.
Integrating a model into your data flow allows you to leverage the Asset Hierarchy to define a set of tags to be sent as input to your model. Additionally, you have the flexibility to generate any number of new tags from the output of your model and use the Asset Hierarchy designer to model the flow for these outputs.
Store
Tricloud Nexus can be setup to store data locally on the edge, or transfer data to cloud storage using multiple endpoints, such as:
- Azure Data Explorer
- SQL Database
- Data lake
- Enterprise Unified Namespace
- Local MQTT Broker
- NoSQL databases (MongoDB, Cassandra, Redis ..)
When using MS Azure IoT hub, data can be streamed in real-time to the endpoint, or alternatively, through blob storage for a more cost-effective solution, when streaming in real-time is unnecessary. This configuration can be set individually for each data point (tag) and can be adjusted during runtime operation.